数据仓库ETL爬虫&数据处理小记
Github Repository
这个链接将在本学期末本人将此repository设为public后可以访问:
https://github.com/Baokker/data-warehouse/tree/main/homework-1-etl
要求
1)获取用户评价数据中的7,911,684个用户评价
2)从Amazon网站中利用网页中所说的方法利用爬虫获取253,059个Product信息页面
3)挑选其中的电影页面,通过ETL从数据中获取
- 电影ID,评论用户ID,评论用户ProfileName,评论用户评价Helpfulness,评论用户Score,评论时间Time,评论结论Summary,评论结论Text,电影上映时间,电影风格,电影导演,电影主演,电影演员,电影版本等信息
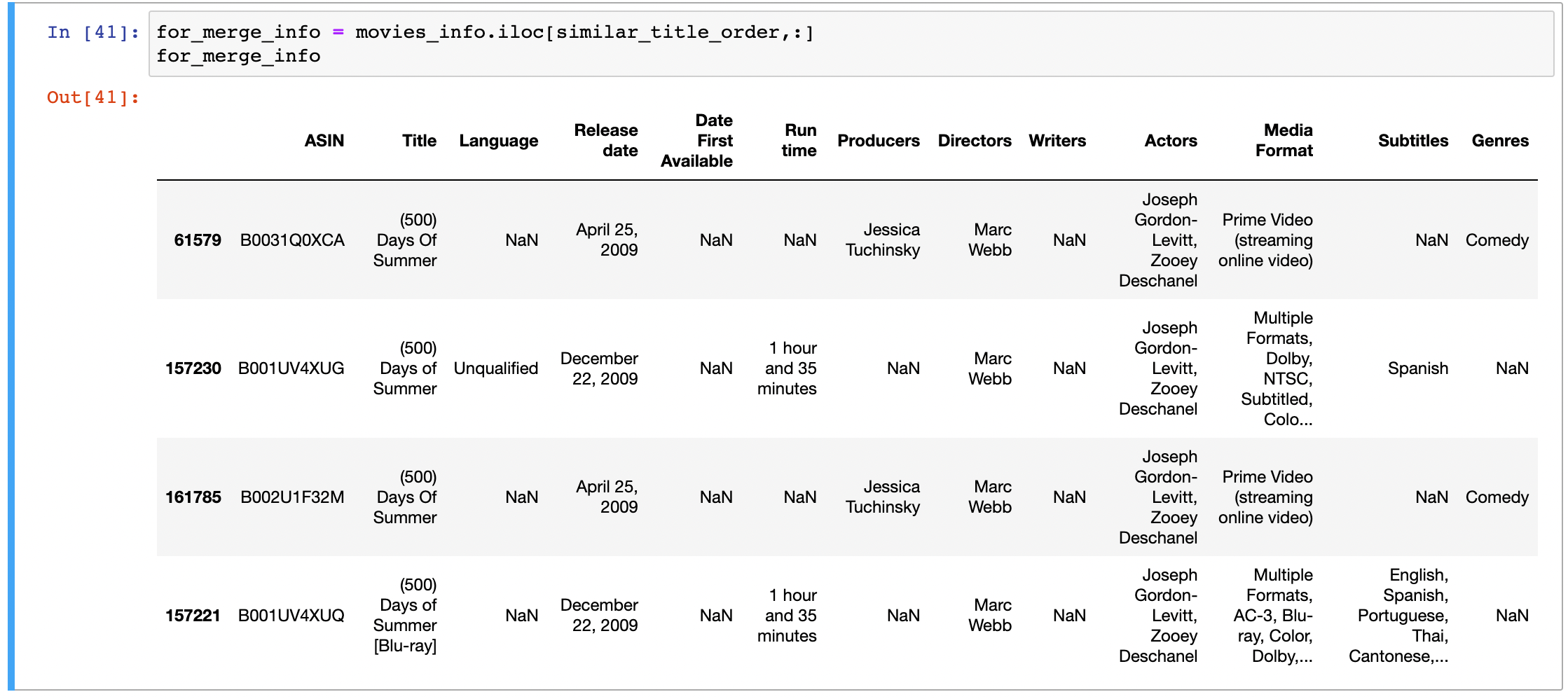
4)在网页中不同网页可能是相同的电影(如同一部电影的蓝光、DVD版本,同一部电影的不同语言的版本等),通过ETL对相同的电影(需要给出你所认为的相同的定义)进行合并
5)在网页中电影演员、电影导演、电影主演等会出现同一个人但有不同名字的情况(如middle name,名字缩写等),通过ETL对相同的人名进行合并
4)在网页中部分电影没有上映时间,可以通过第三方数据源(如IMDB、豆瓣等)或者从评论时间来获取
5)通过ETL工具存储Amazon页面和最终合并后的电影之间的数据血缘关系,即可以知道某个电影的某个信息是从哪些网站或者数据源获取的,在合并的过程中最终我们采用的信息是从哪里来的。
- 可以参考的工具:
- Pentaho Data Integration: https://sourceforge.net/projects/pentaho/ (Links to an external site.)
- Web爬虫:https://scrapy.org
Tree(文件大纲)
1 | |
获取用户评价
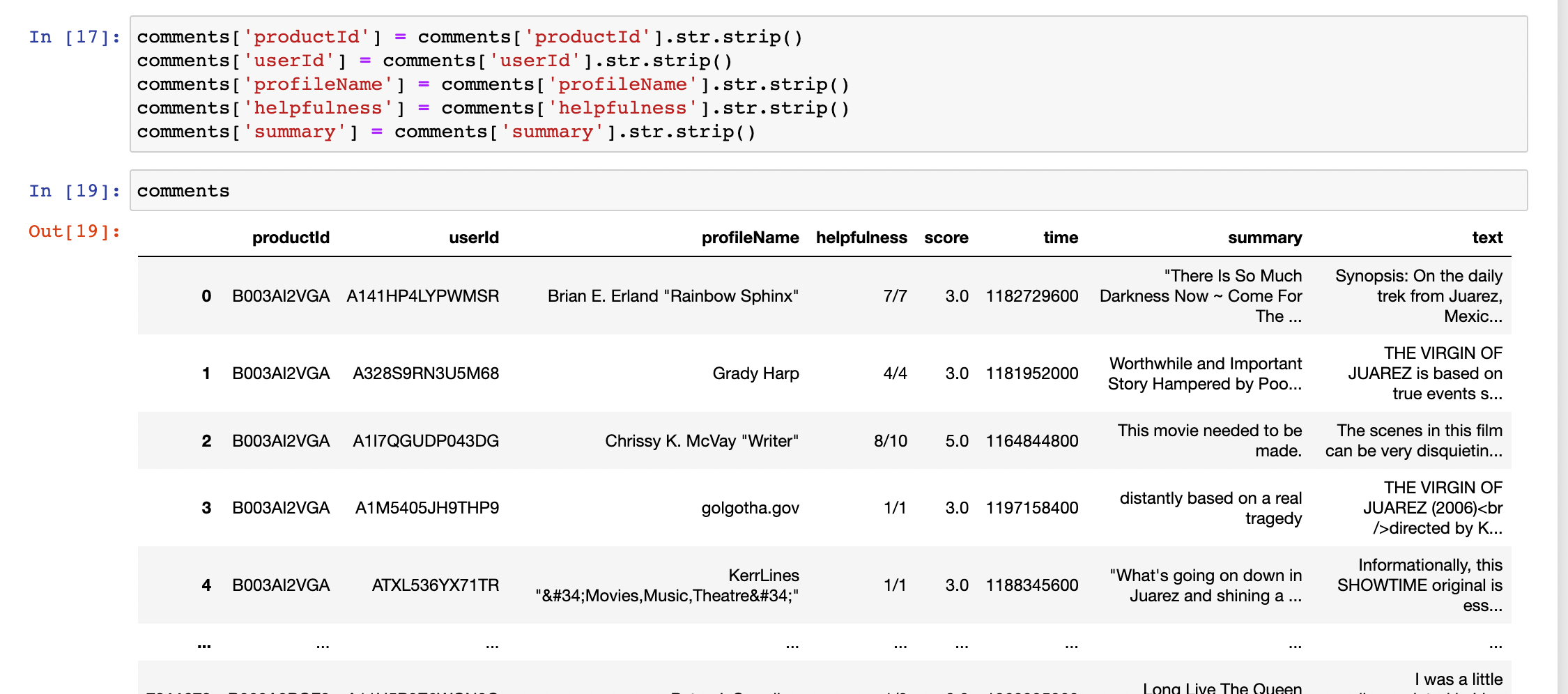
首先打开要求中给出的snap网页,观察可发现,它提供了一个下载链接,用于下载十多年来由约九十万用户发出的与二十五万产品相关的近八百万条评论。
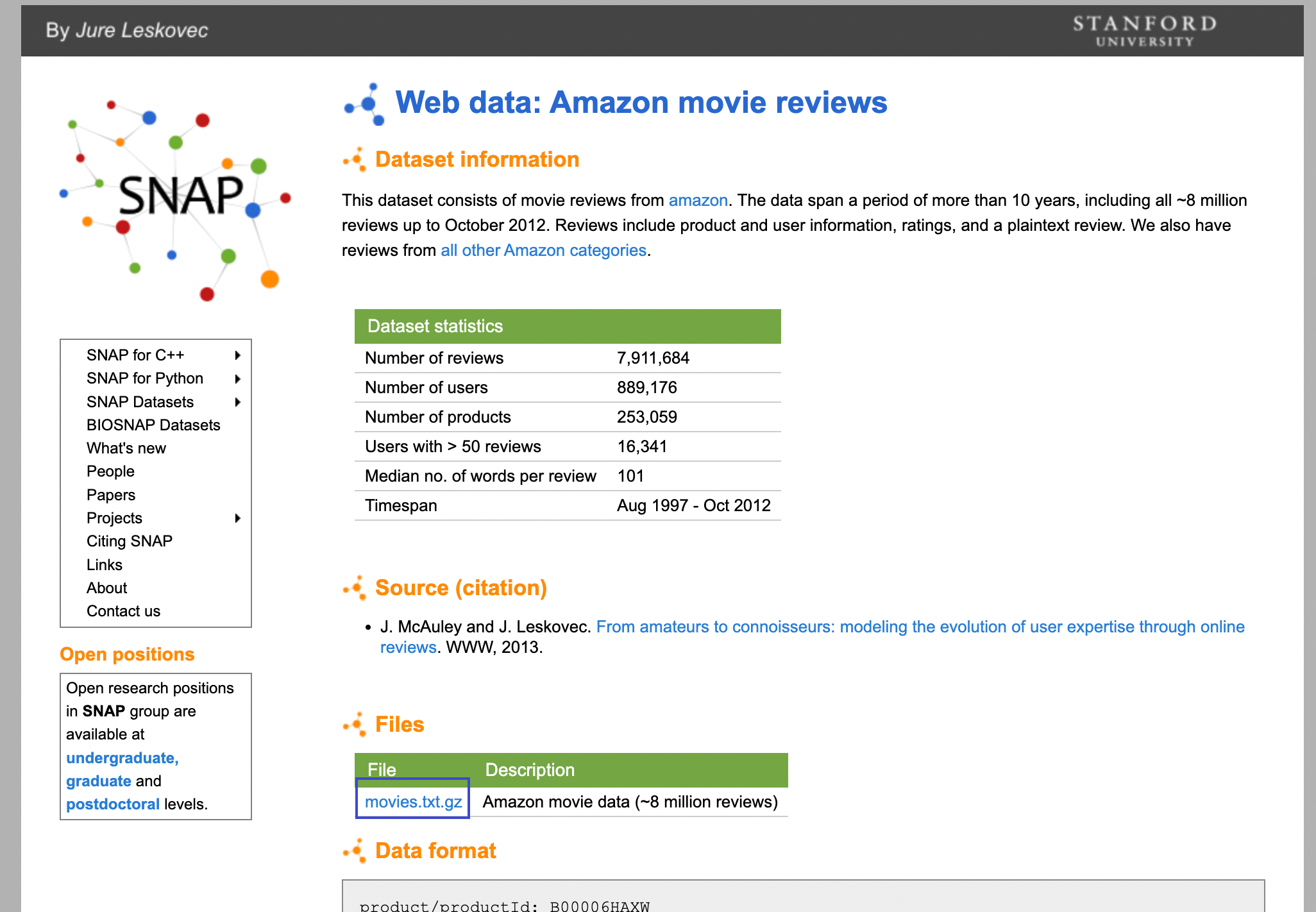
下载压缩包后解压,会得到一个将近9G的movies.txt文件,里面的文本格式基本如下所示,其中productId即为每个产品对应的亚马逊产品号(ASIN),并且都是唯一的。

由于文本格式非常整齐,因此可以直接用Python逐行读取,提取内容。
具体代码见extract_movies_txt.ipynb
1 | |
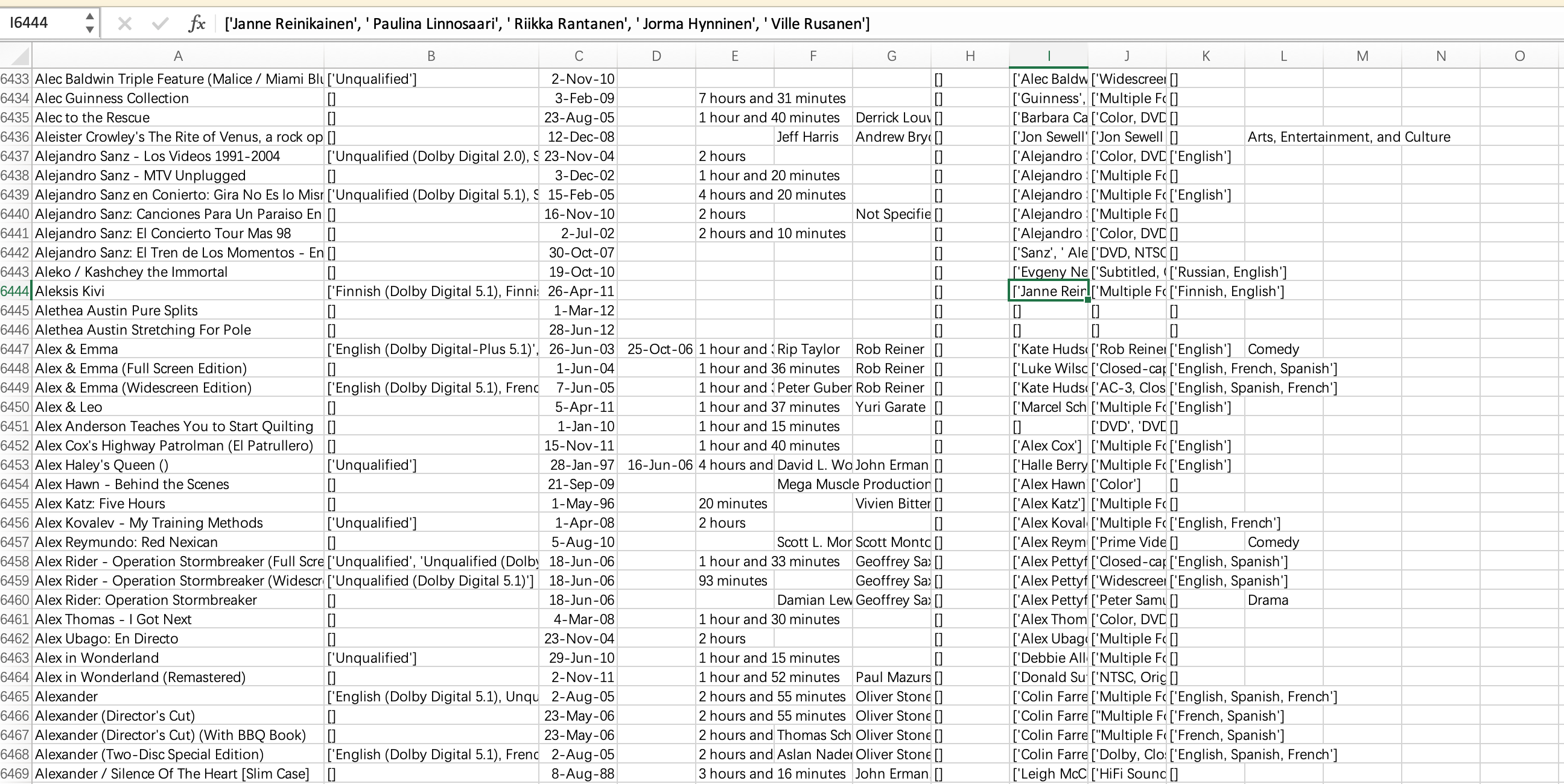
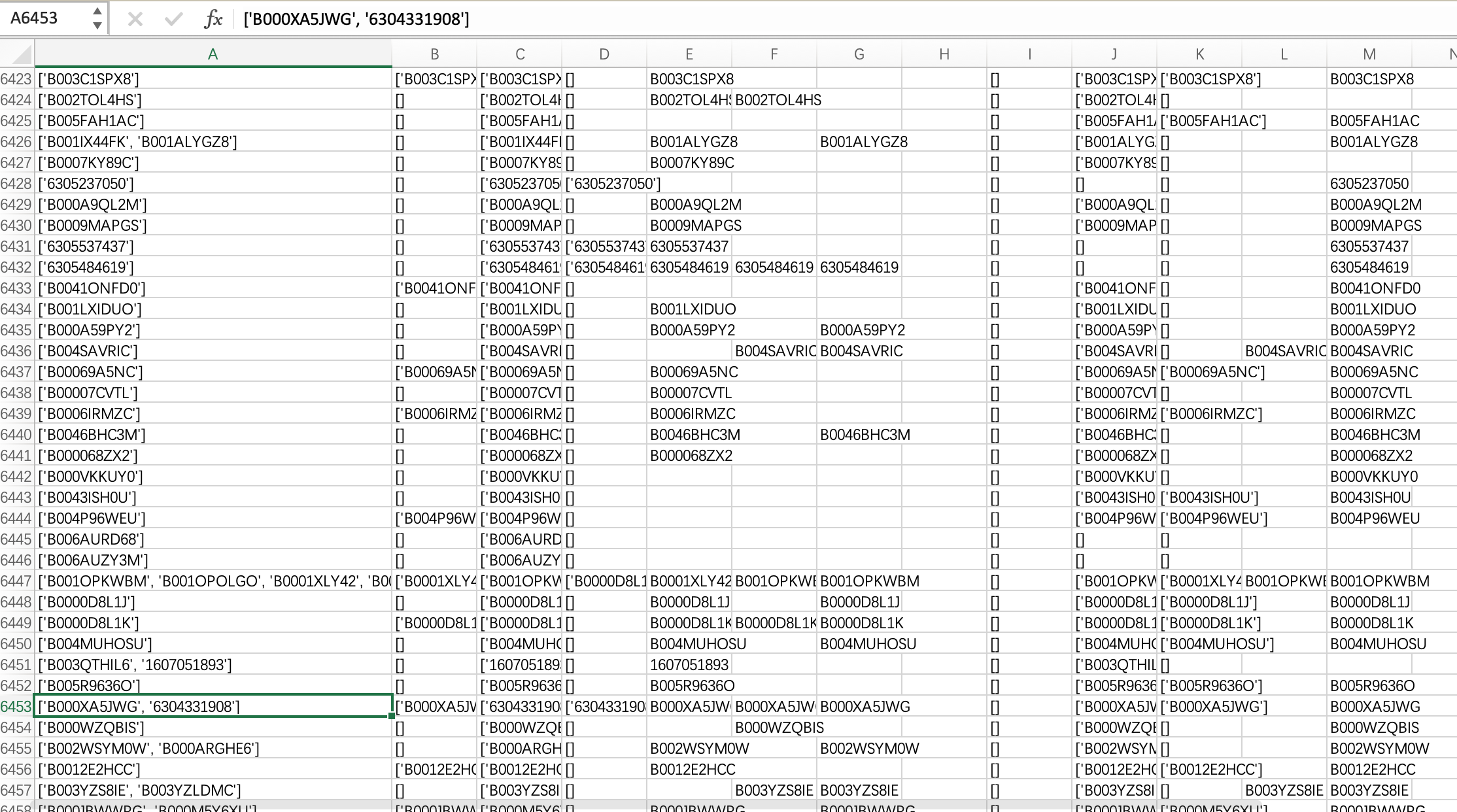
逐行读取并用split函数提取内容,再用pandas导出为csv保存,最后得到一个约8G的csv文件,里面包含评论的各种信息
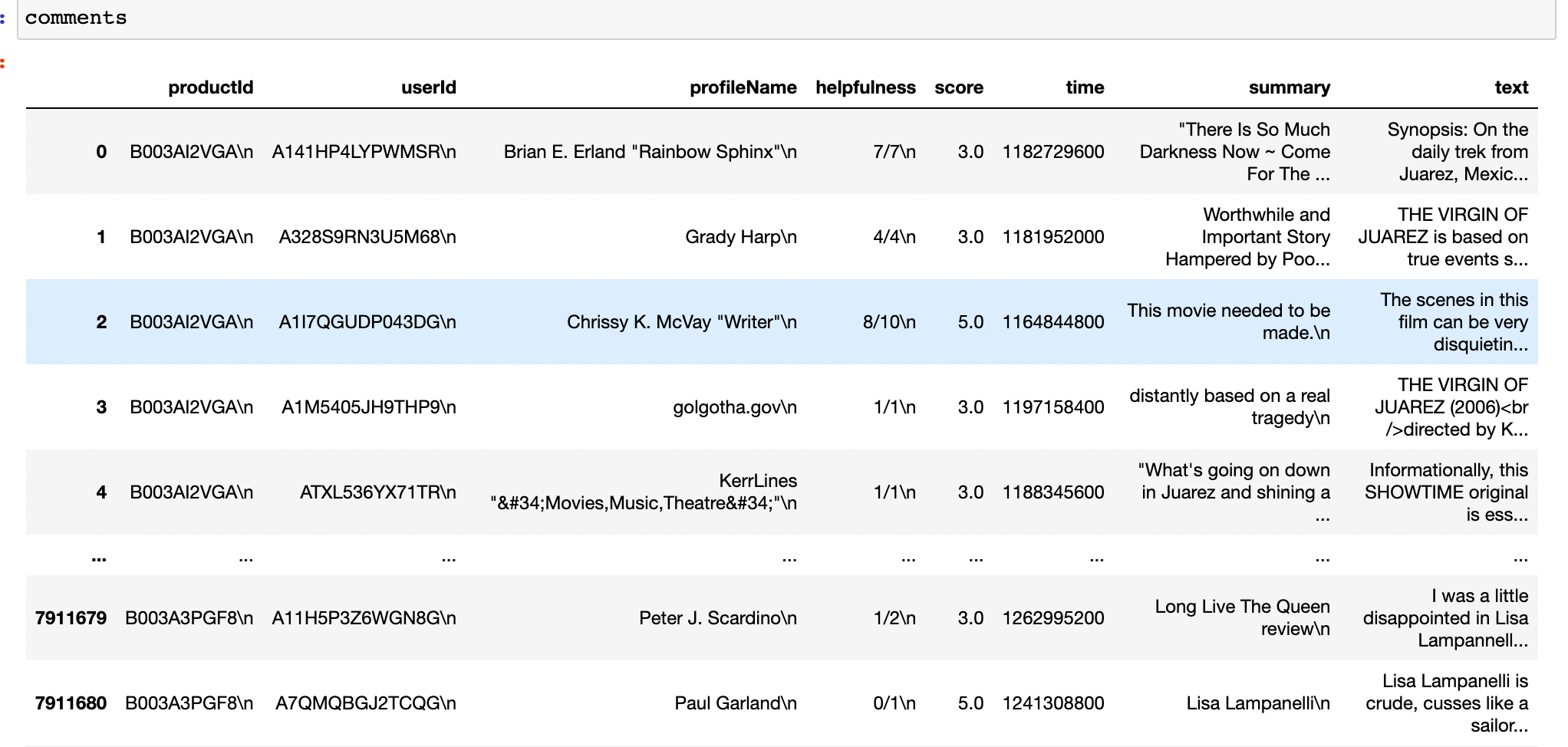
可以看到,提取过程中并没有对换行做出很好的处理,因此用pandas导入后再进行处理,去除换行(get_date_from_comments.ipynb)
1 | |
可以看到,经过处理后,基本达到了一个较好的效果
爬取网页
获取ASIN
由官网介绍可得,每件产品对应的网址,其实就是amazon.com/dp/$(ASIN),其中ASIN为对应的产品编号


为此,首先在movies.txt中提取ASIN(extract_movies_txt.ipynb),并保存为productId.csv
1 | |
定位网页内容
接下来对网页内容进行爬取。在此处使用Scrapy+Selenium进行爬取网页内容,具体内容如下:
首先安装Scrapy,再使用scrapy自带的命令行查看和分析单个网页
https://www.amazon.com/dp/B00006HAXW/
1 | |
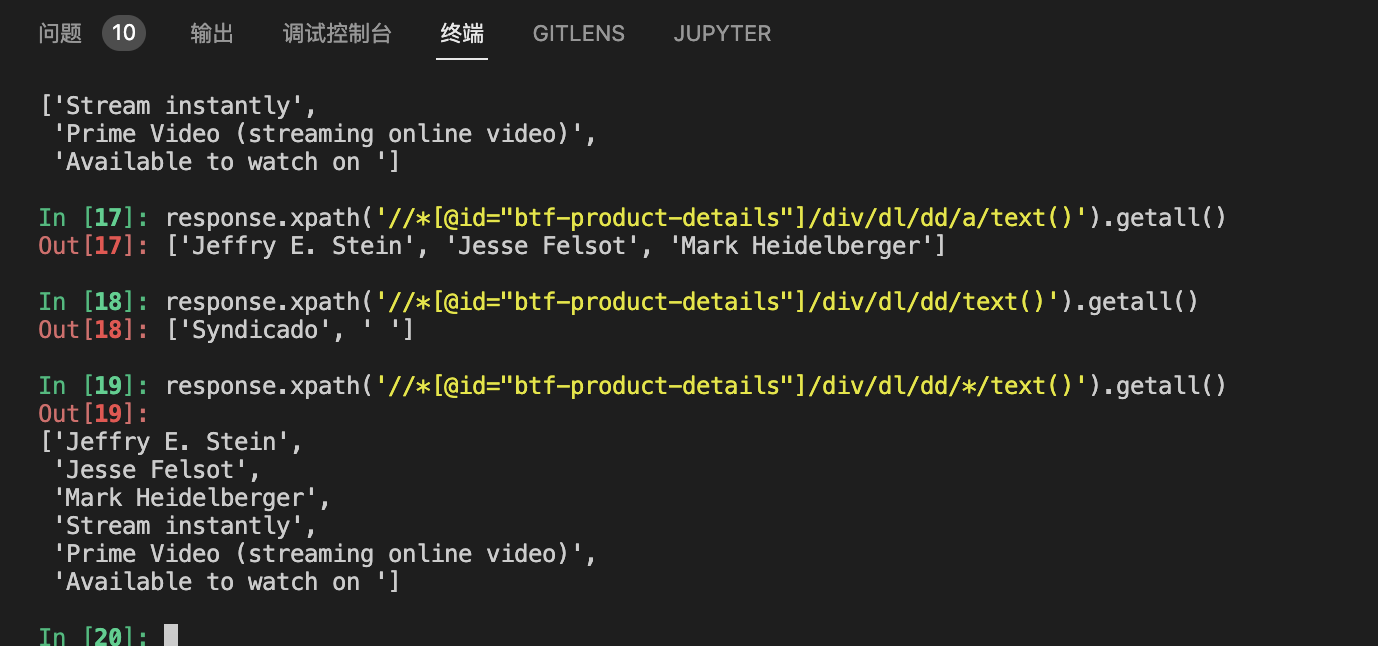
之后可以在命令行中通过view(response)方法查看页面,也可以通过response.xpath('...').get()的方法获取数据。(xpath是一种XML路径语言,相比css更容易确定HTML页面中的位置
xpath的语法不难,但是浏览器自带的开发者工具提供了更为方便的方式。在网页内容中右键选中对应的标签块(例如,<span>,<h1),右键即可复制其对应的XPath,并查看相关内容
经观察,亚马逊的电影网页分成正常和Prime Video两种
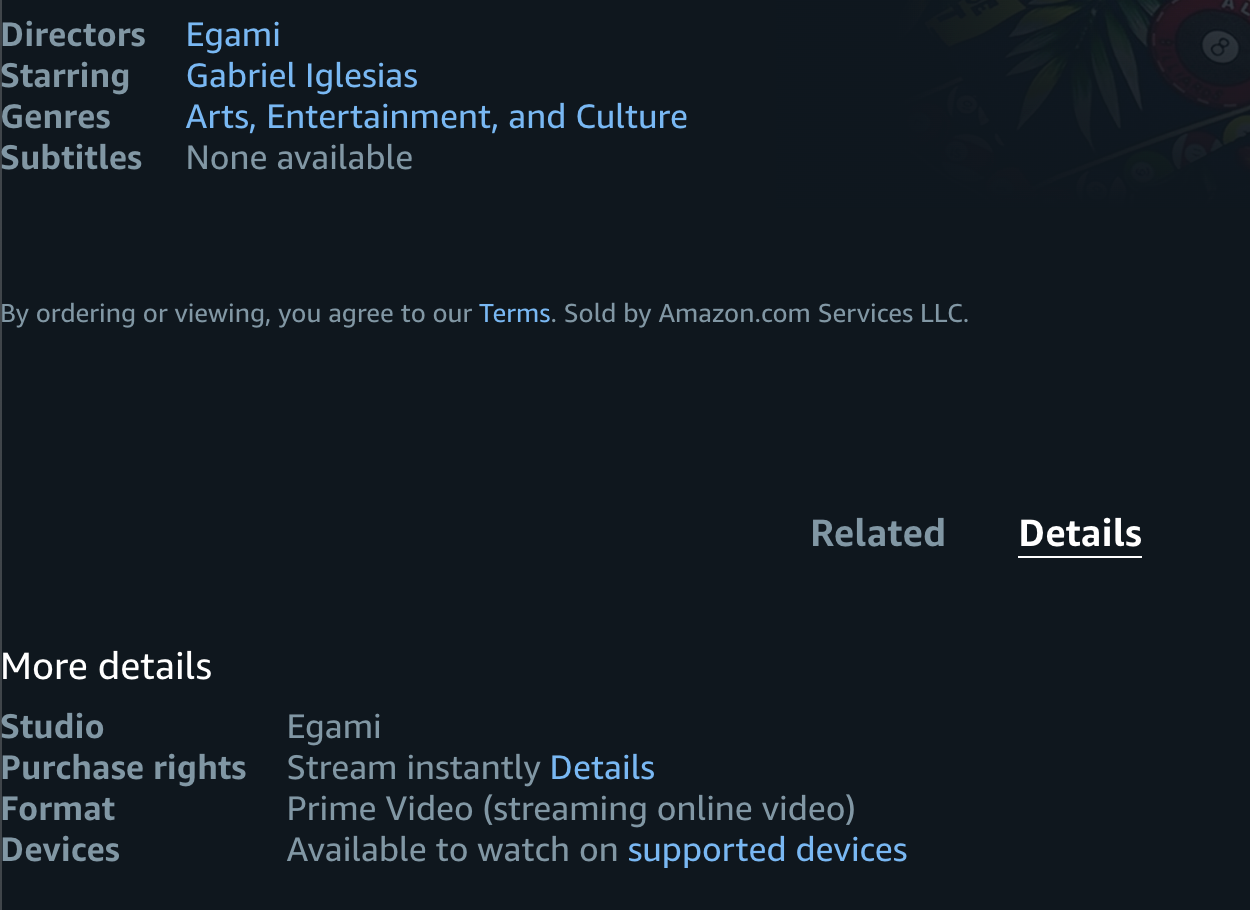
正常页面如下
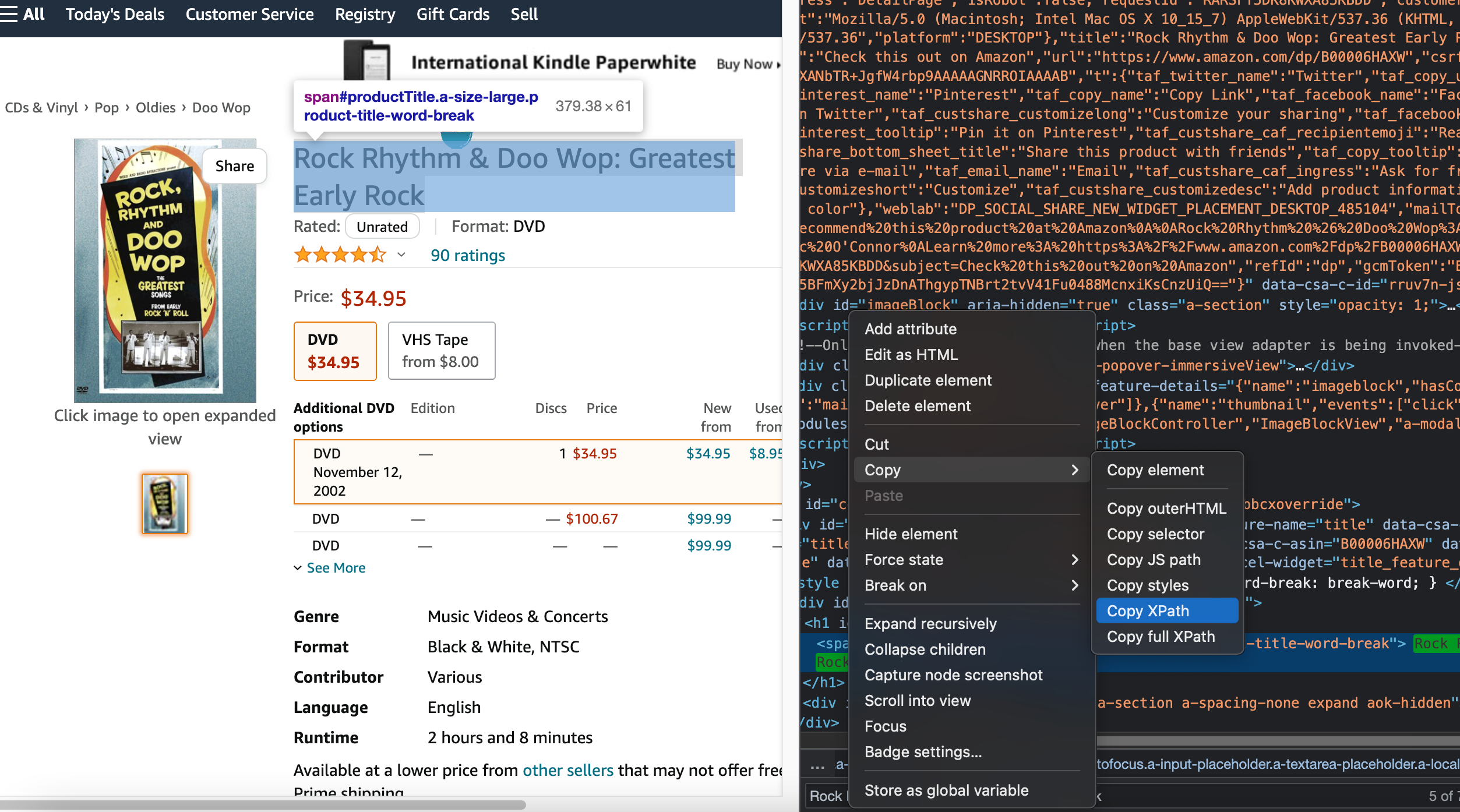
经观察,爬取了这部分以及标题的内容
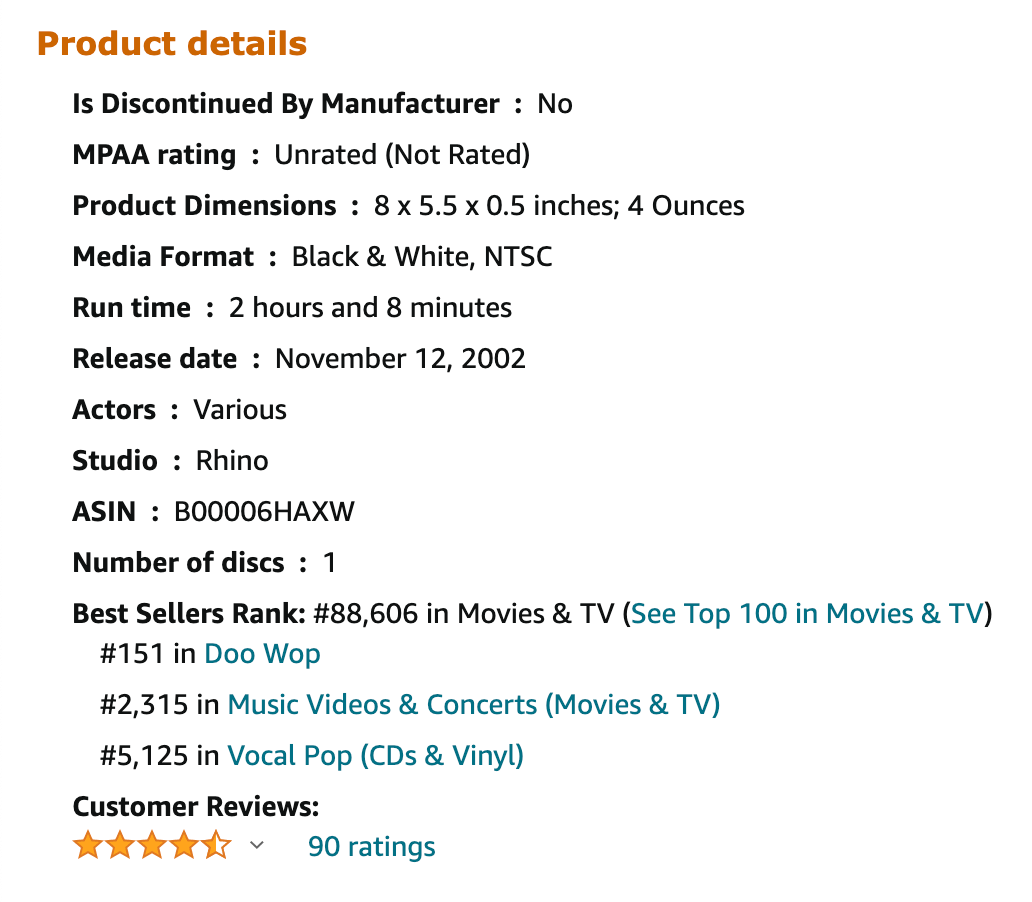
Prime Video的页面如下
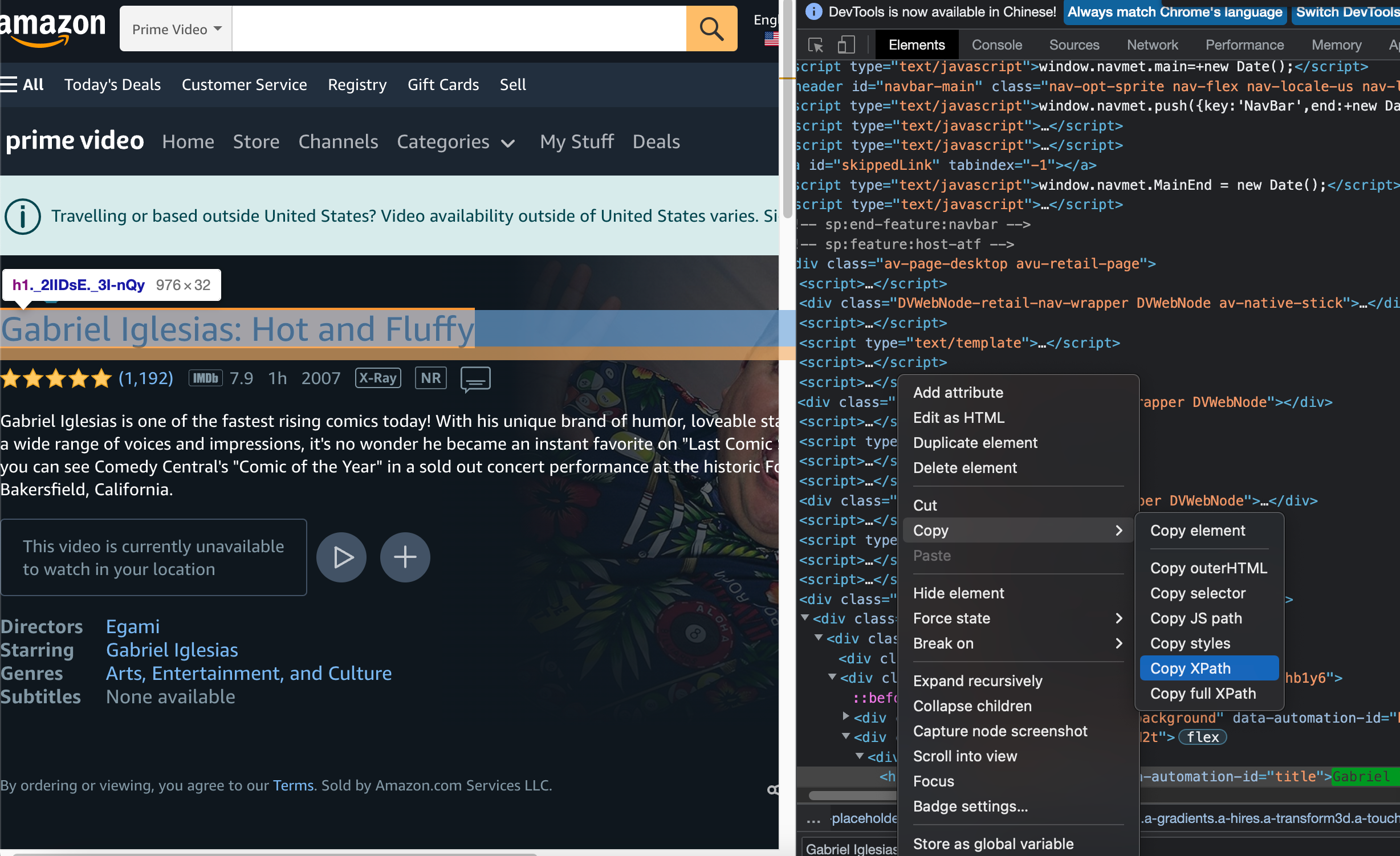
主要选取了以下部分内容
开爬
接下来使用scrapy创建项目
1 | |
在FilmInfoSpider/FilmInfoSpider下建立py文件,并写入爬虫脚本,爬取的链接为上文中提取的25w个产品对应的网址
核心部分代码如下:
1 | |
具体来说,首先根据搜索框里类别来判断网页的类型,如果是Movies & TV,那么就按普通页面的的内容获取标题和内容;如果是Prime Video,则再判断该类型是否为movie,是则提取网页内容。
此外,为以防万一,将每次访问的网页内容也写入到文件,方便后续调用
反反爬
然而亚马逊具有很强的反爬机制,没过多久就要求我输入验证码验证,大致图片如下:

另外,对于请求过度频繁的ip,亚马逊也会禁止其访问内容
对此,需要进行反反爬措施。有ip池代理+伪造请求头的方法,也有使用Selenium模拟手动打开的方法。Selenium本身是为Web浏览器提供的一个测试工具,为测试的自动化提供了一系列方法,由于其在某种程度上说类似于模拟人进行浏览器的操作,相比单纯的发送ip请求,可以绕过更多限制,减少反爬的可能,因此也有越来越多采用Selenium进行爬虫的方案。此处采用了Selenium作为scrapy的middleware,先用Selenium打开一个浏览器,再打开制定的网页,并作为response返回。
核心代码如下:
1 | |
这里主要有两个要点:
- 经过一定的爬取后,发现数据并不完整,经过debug发现,网页在加载时不一定能完全加载完,下面的Product details可能不会加载成功,而是变成一段sorry的话,再刷新后才会正常显示。因此在每次Selenium获取网页后,调用
refresh()方法再次刷新 - 爬取时有较小概率出现验证码的问题。经过查阅,发现github上有一库为
amazoncaptcha,可以根据传入的图片链接获得对应的验证码数字。于是先用xpath获取验证码图片的链接,再用amazoncaptcha得出结果,并用Selenium模拟输入验证码并按下按钮,即可解决验证码的问题
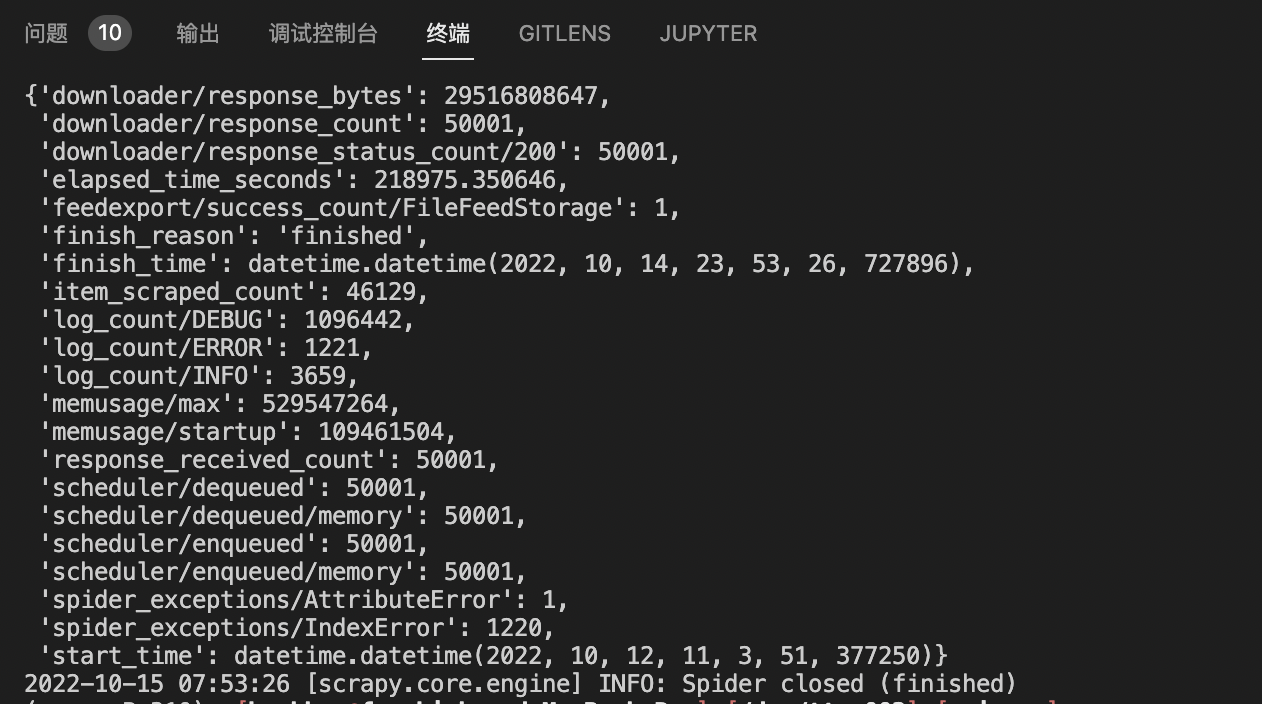
解决这些问题后,连开五个进程进行了爬取:
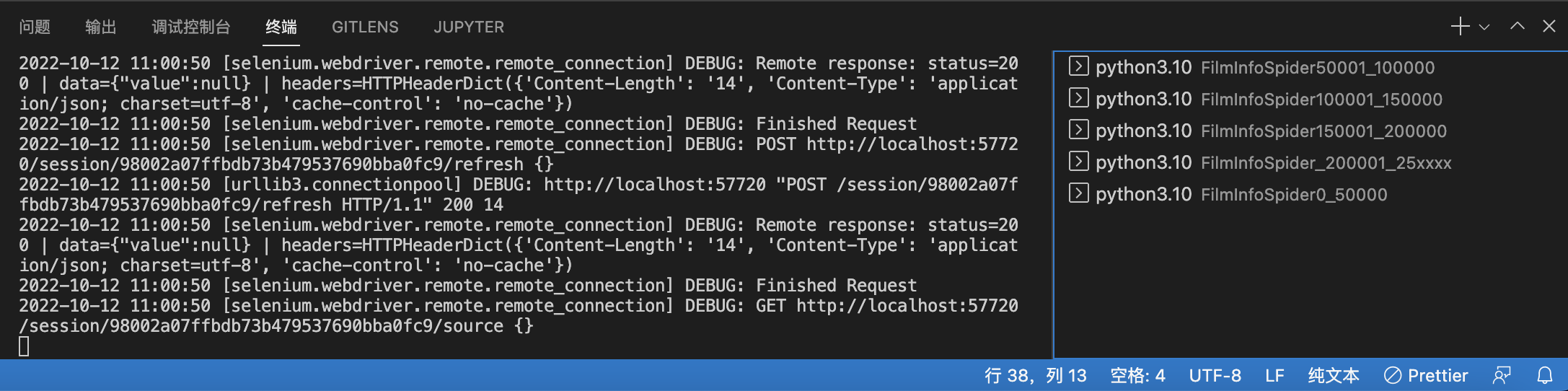
(忘记截屏15w-2ow的了..)
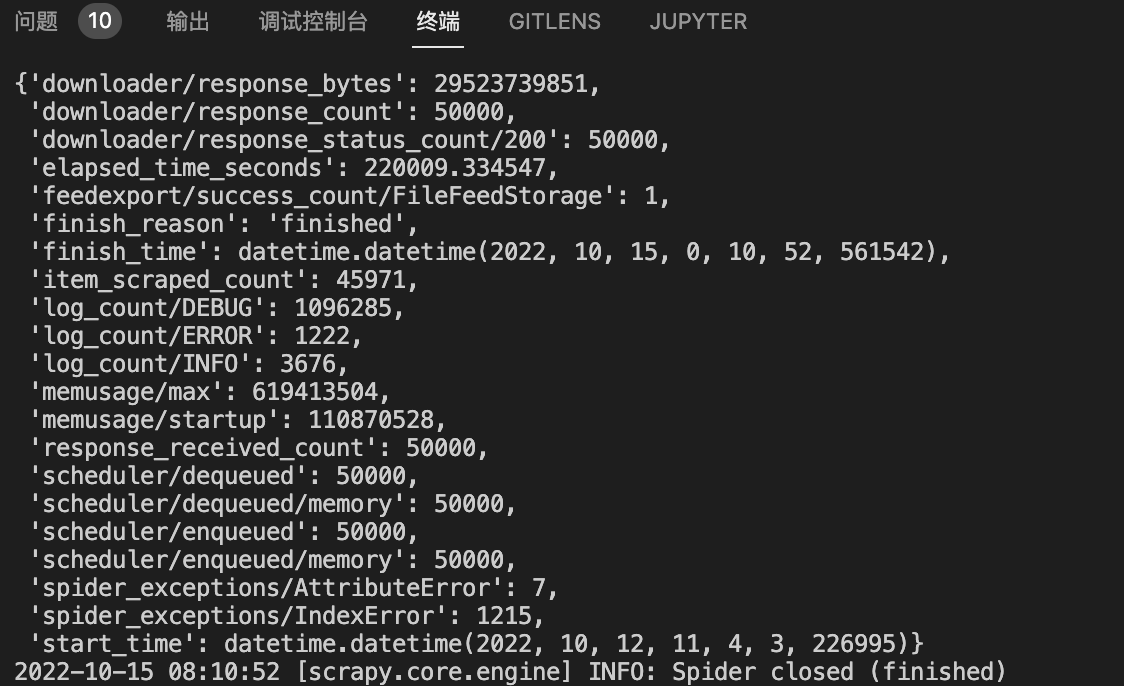
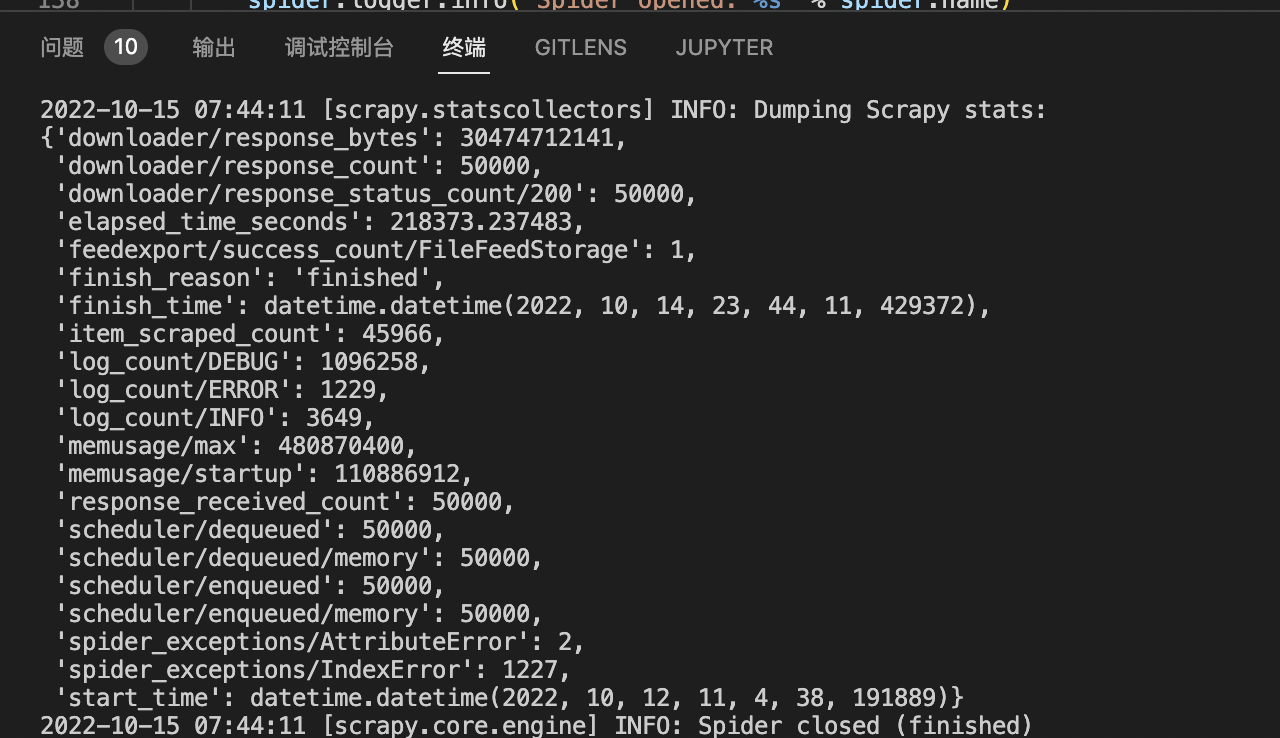
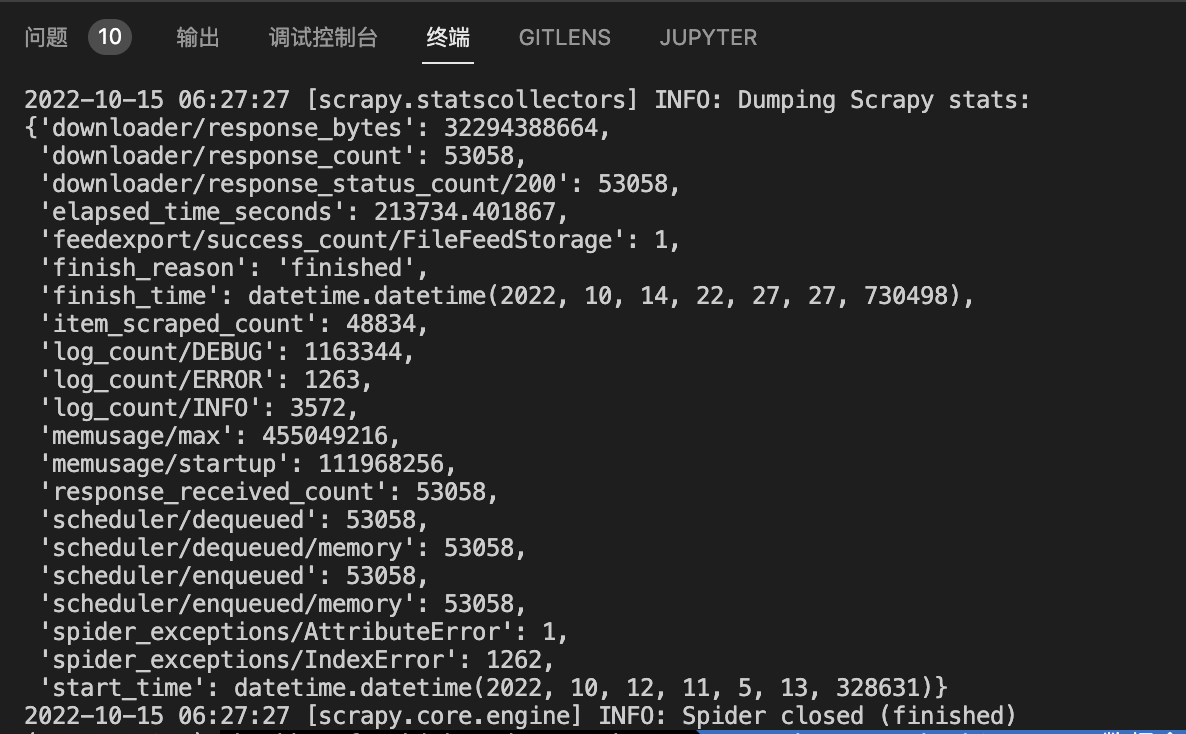
补爬
爬取完数据后,发现部分数据没有Title,检查后发现是Prime video检索标题的Xpath有误
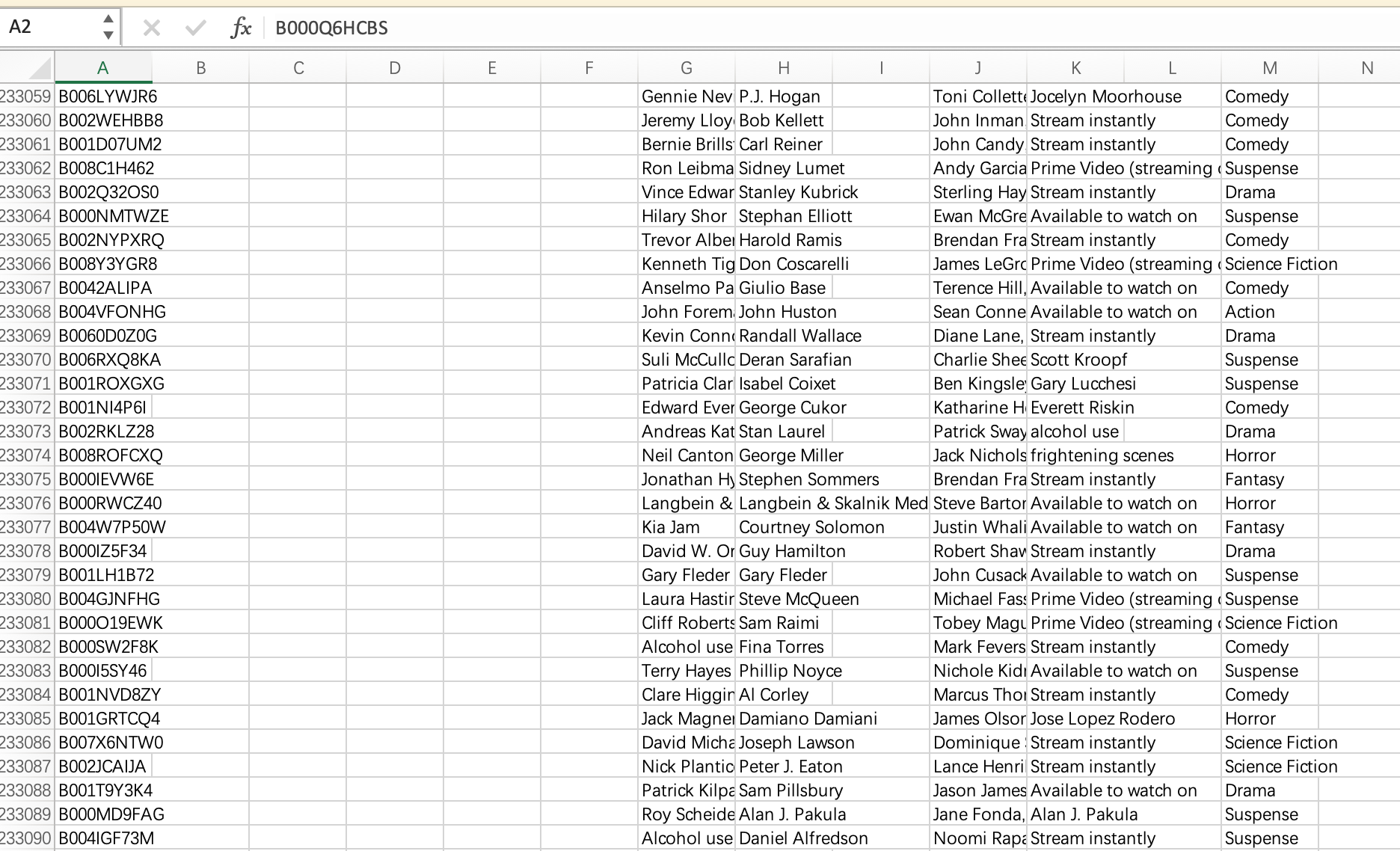
所幸在之前保留了网页的文件,因此修改代码后,使用scrapy对本地文件爬取即可
1 | |
由于仅是本地文件,也不存在反爬的可能,直接用默认的middleware即可
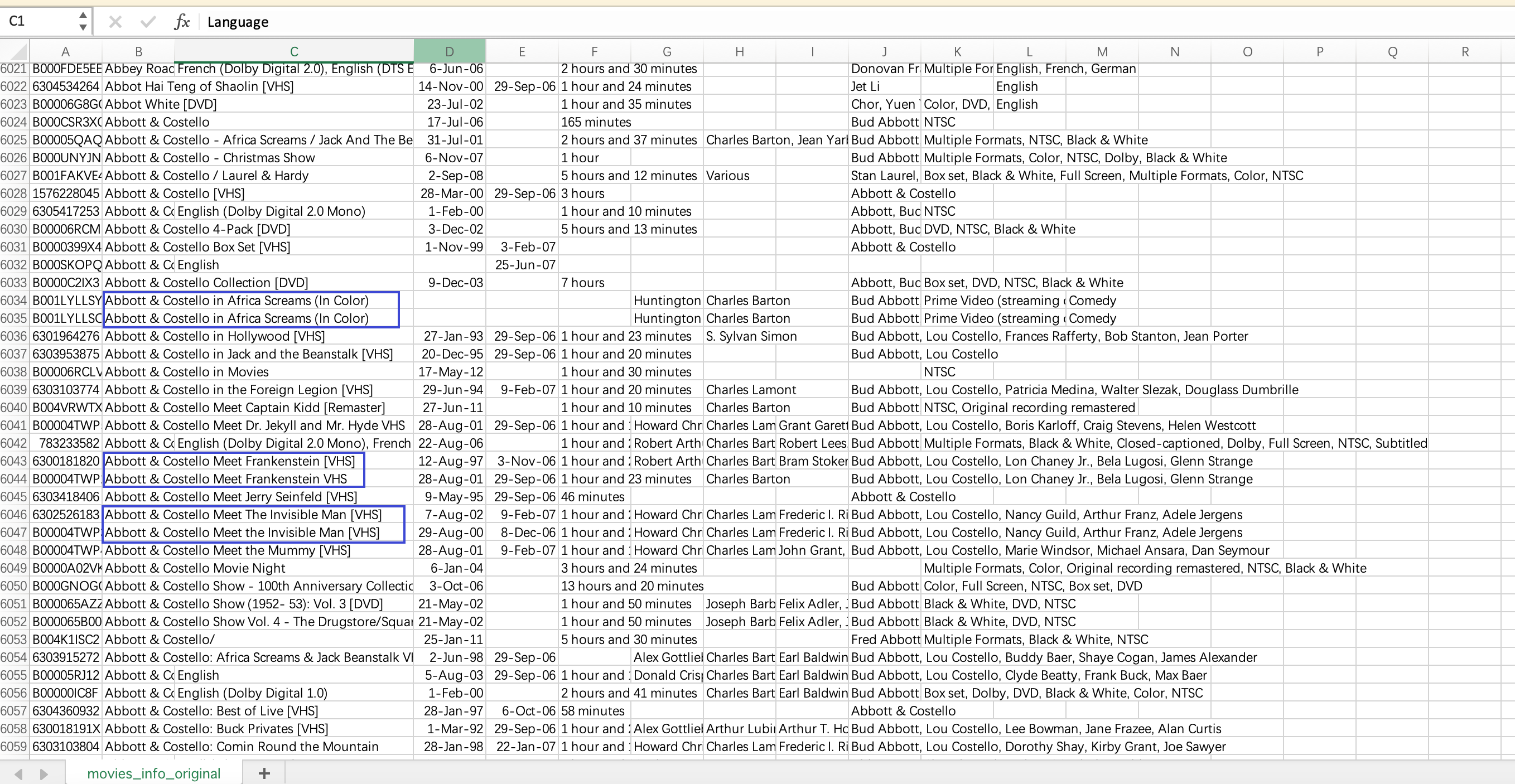
合并相同电影
观察电影标题,可以发现很多电影其实是一部,无非是版本(VHS,DVD,Blu-ray),或者是放映年份的区别。为保证数据的质量,对相似的电影进行合并
在此处,主要采用pandas+fuzzywuzzy的方法合并数据。pandas是一个著名的python的数据分析库,在处理数据方面工具齐全,性能较快;fuzzywuzzy是一个匹配字符串的库,采用Levenshtein Distance计算字符串直接的相似度
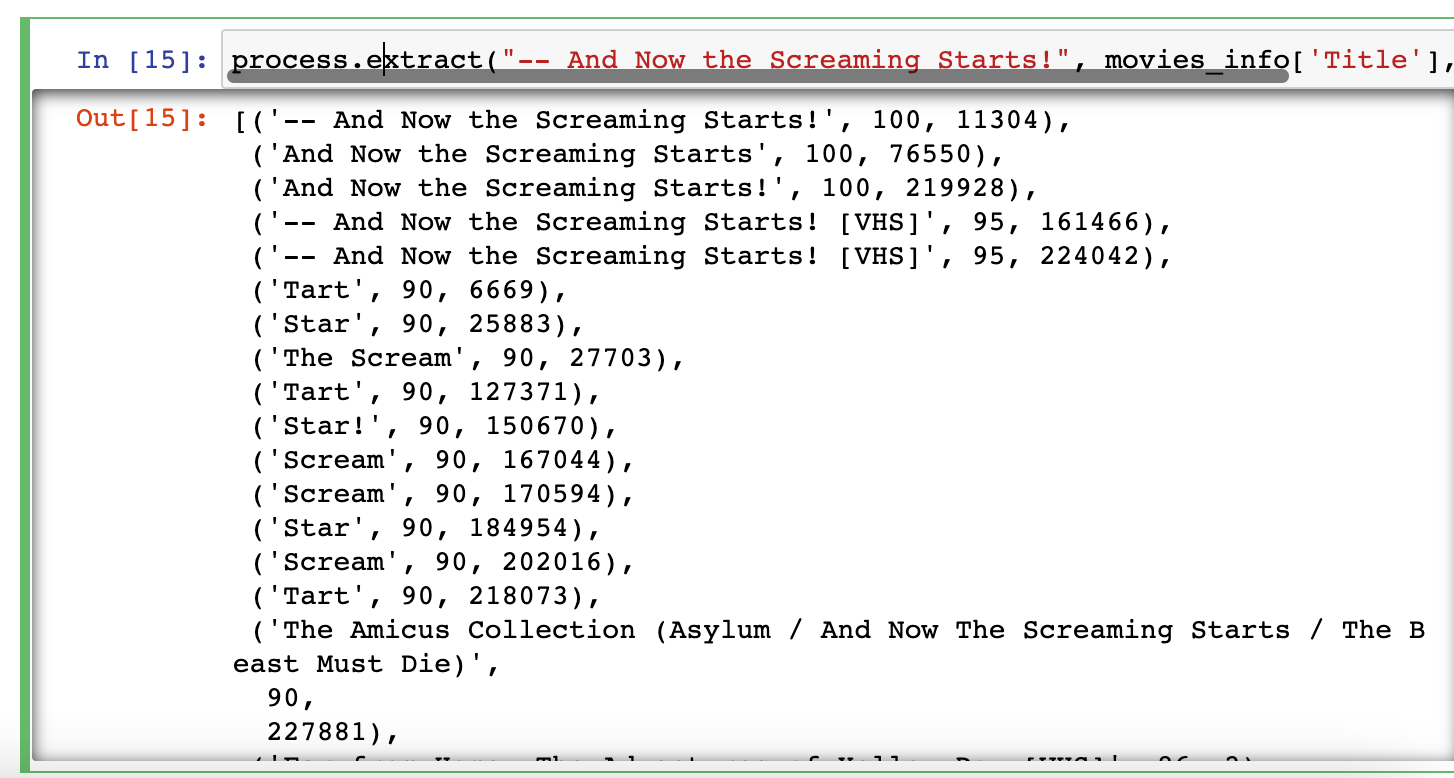
针对合并相同电影的需求,给出如下方法:
- 首先去除Title中关于版本的信息(VHS,DVD等),并删除最外边多余的引号
- 利用Levenshtein Distance计算相似度,选取那些得分高于95的,视为同一电影
- 在合并电影时
- Title选名字最短的
- Release Date,Date First Available选最早的
- Run time,Producers,Directors,Writers,Actors,Genres一般出现的都不会有不同,选取第一个出现的
- Producers,Directors,Writers,Actors使用列表分割
- Media Format,Subtitles将所有可能的结果纳入到一个集合中
核心代码见merge_same_title_and_record_source.ipynb
1 | |
另外,考虑到fuzzywuzzy在计算大量距离时耗时较长,因此先将电影名排序,再将每部电影与之后10部电影的相似度进行比较,从而减少了运行的时间
合并人名
人名的格式不尽相同,有时相同的人会有不同的名字,情况如下:
- 人名颠倒,或者缺少空格
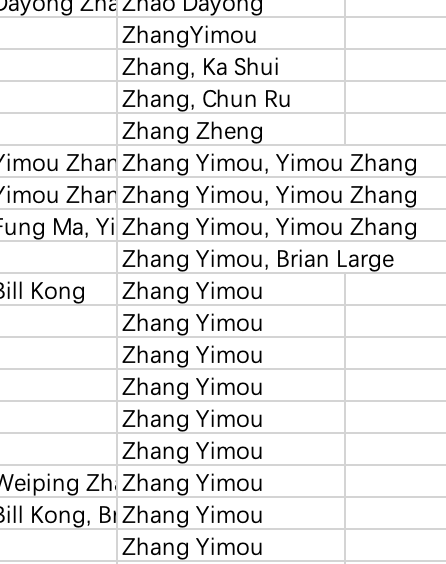
- 大小写不同
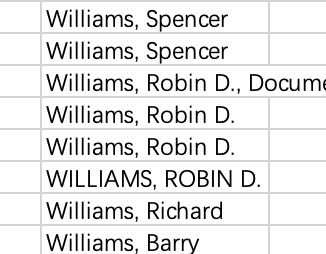
middle name缩写


经过测试,仍采用fuzzywuzzy库进行相似度比较
- 首先读取电影信息,抽离出所有导演,编剧和演员的名字,合并到names数组中
- 对其进行去重,降序排序
- 这样是为了保证更加规范的小写字母的名字在前,以确保替换时以先遍历到的规范名字在前
- 遍历数组,计算首字母相同的名字之间的相似度,选取得分高于95的进行替换
(具体代码见merge_similar_names.ipynb)
上映日期
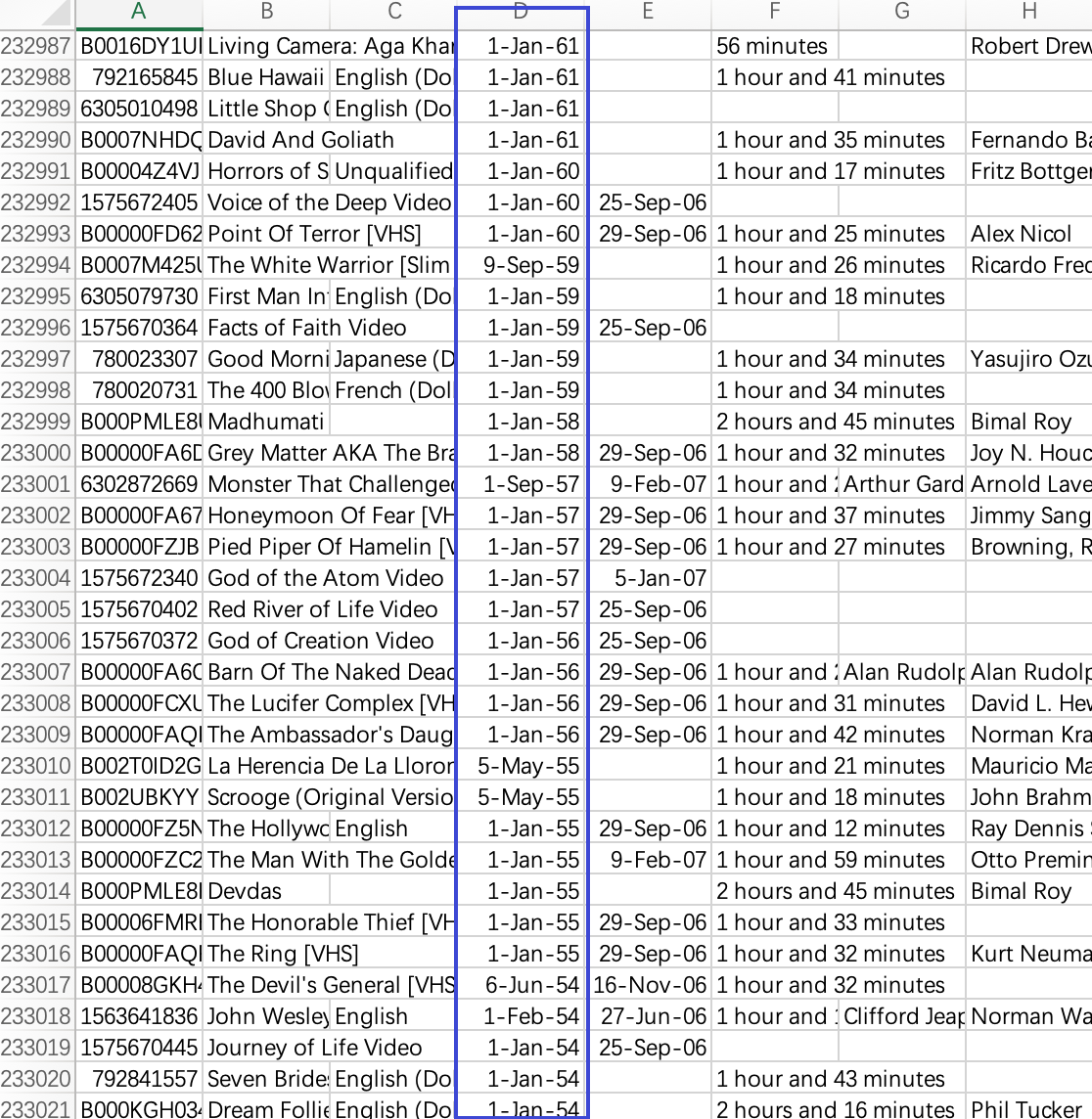
部分电影缺少上映日期。对此,从之前提取的评论数据出发,选取对应ASIN值的评论中最早的时间,将其定义为上映日期
1 | |
结果如下
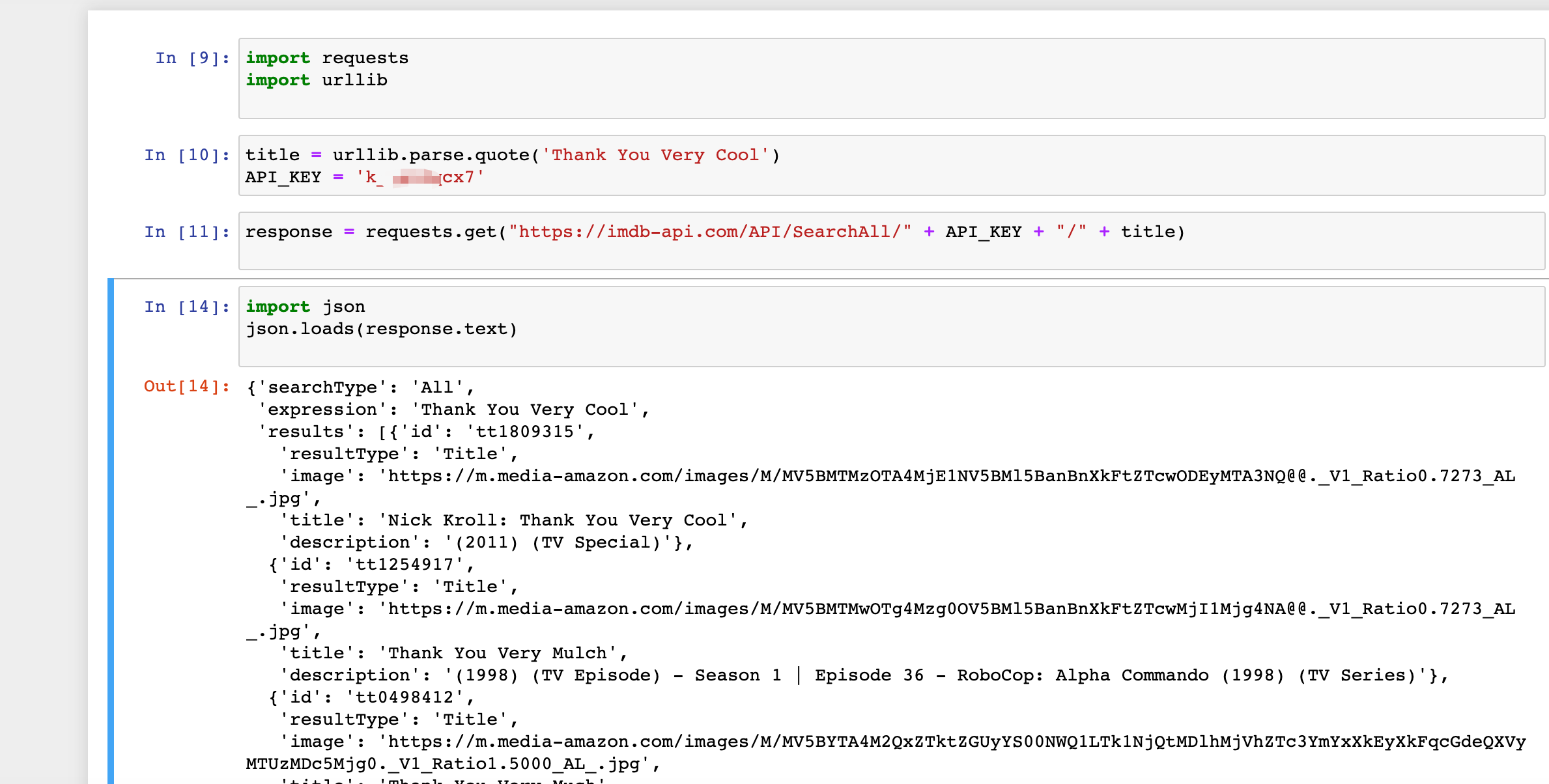
此外,经调研发现,imdb提供了若干API接口,只需要在imdb developer上注册一个账号,申请API_KEY,就可以根据文档描述进行查询。简单的示例如下:
数据血缘
在合并相同电影的同时,建立了一个新的名为source_asin的DataFrame,列的信息与电影信息相同,行数也保持一致,而每个单元格的信息则是对应电影信息表中的数据的来源ASIN值。通过这种方式,可以找到每个信息的来源