一口气更新本学期代码经验心得
ChatGPT Copilot
可以说这学期给我的代码开发带来最大变化的就是这两款工具了,一款帮我生成代码或者特定的指令,一段潜伏在IDE里,读取我的上下文和注释,帮我缝缝补补生成代码。
ChatGPT由于之前封禁了一大波号,一段时间没敢用,反而让我在网上接触到了一些镜像网站,非常方便使用。在这里仅给出链接,具体还请各位自己探索。我在这里放一些使用的截图。
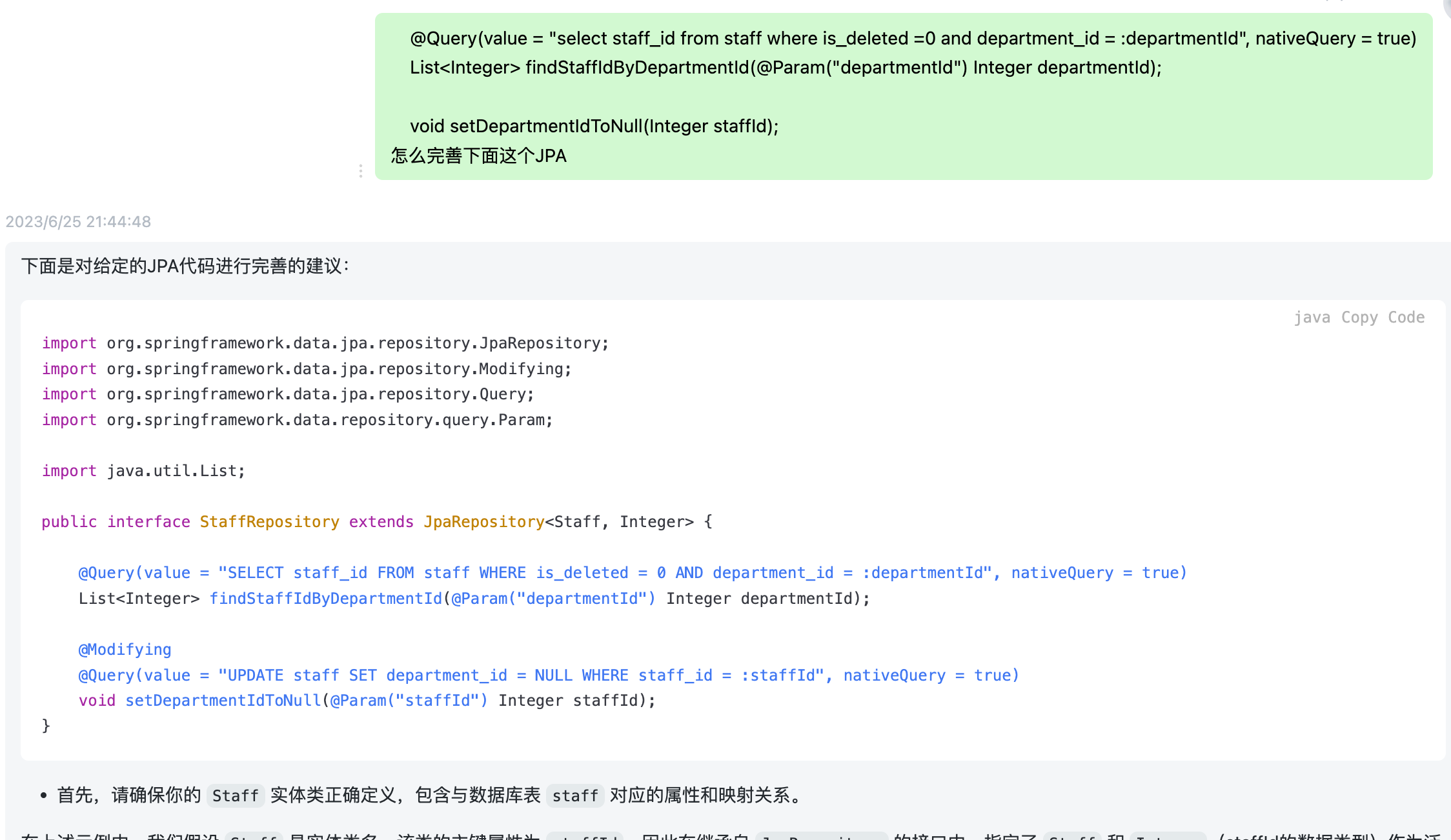

基本上当我遇到错误报告,代码不知道怎么写,Linux命令想不起来怎么做,或者想偷个懒让他帮我写点东西时,我都会使用它给我提供建议或者初稿,而我只消稍加润色即可完成。
而copilot在我申请了GitHub Pro之后,则成为了我编写代码的利器。一般来说,我只需要把光标悬浮在那边,它便能为我补充代码
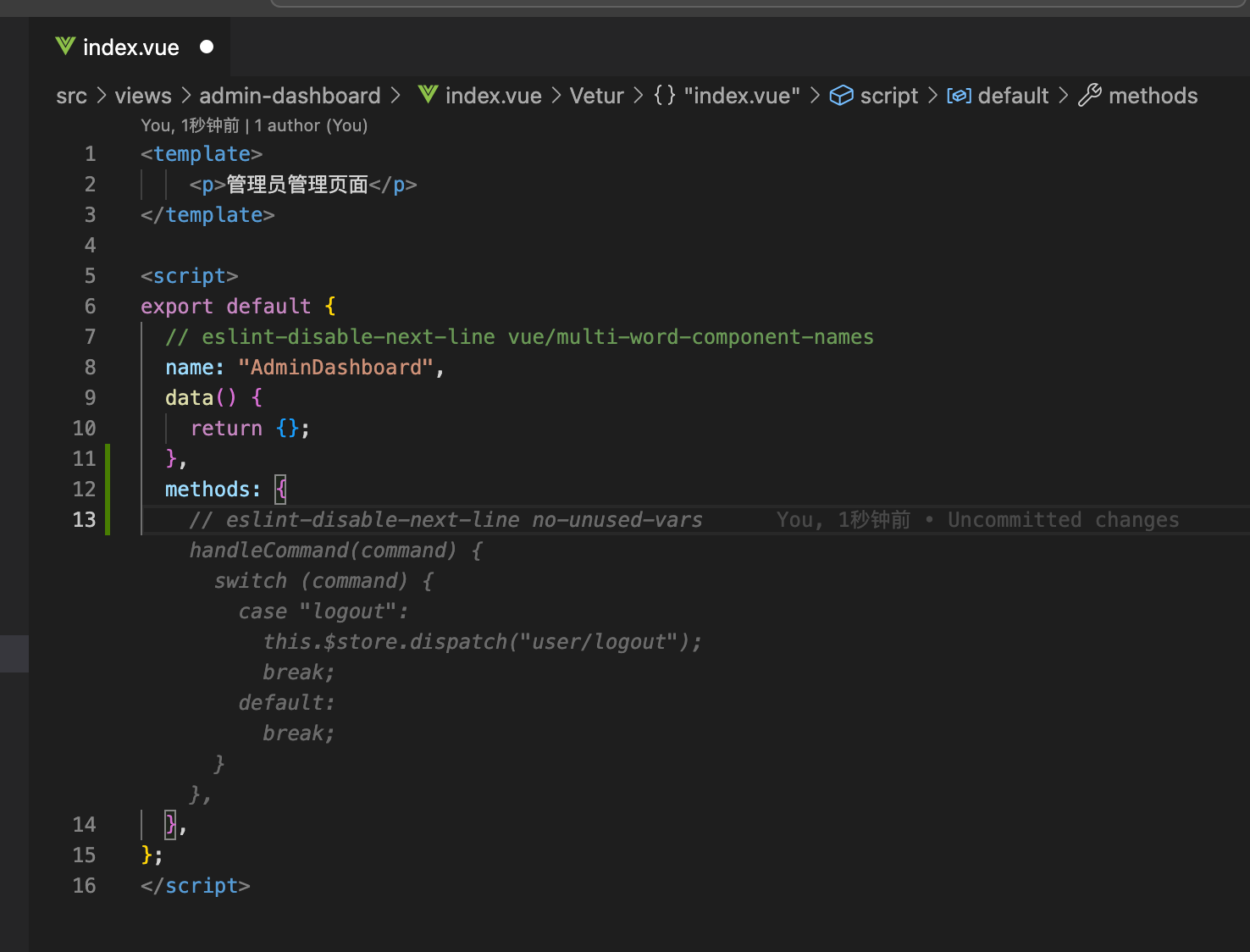
不过经过我长期的使用,我发现更有效的方法是,先写一两行注释,让它明白我的意思,再让它自动生成,往往更为高效

这两款工具在根本上改变了我的workflow,所以我要将它们放在最前面。具体来说,原先我的工作流是这样的:
- Google了解一下这个语言/框架
- Google大概了解一下语言/框架的上手方法
- 结合网上的教程,摸索出一个可以跑的框架
- 进一步完善需求
- 如果碰到bug,继续Google解决相关问题
但是拥有这两款工具后,我的工作流变成了:
- ChatGPT教一下我这个语言/框架
- ChatGPT帮我搭好了能跑的框架,并教我怎么上手
- 我进一步完善我的需求,但是中途大部分其实是copilot帮我生成的,我只是在按tab键,然后检查它写的对不对(大多数时候写得比我好)
- 如果碰到bug,先问问ChatGPT
- 实在没解决,或者意识到这个问题它是解决不了的(知识库不够新,跟不上版本,问题太复杂等等),由人脑解决(搜索Google,加上自己思考)
可以看到它们帮我减少了相当多的负担,并且它们的出现让我意识到,这些劳动已经逐渐成为了人工智能的简单工作,而我也不能仅仅是原地踏步,停留在掌握CRUD上。现在更关键的能力是,如何掌握让人工智能帮助我提高生产力,以及挖掘出自己与人工智能不同且更高级的地方。
C语言
好久没写c,结果某同学给我发来几道题把我看傻了。例如
1 | |
在c里面居然是对的。查阅了一番,得到了这样的解答:
If you’re using
gccas your C compiler, you can use designated initializers, to set a specific range of the array to the same value.
2
3// Valid only for gcc based compilers
// Use a designated initializer on the range
int arr[9] = { [0 ... 8] = 10 };Note that there is a space between the numbers and there are the three dots. Otherwise, the compiler may think that it is a decimal point and throw an error.
2
3
4
5
6
7
8#include <stdio.h>
int main() {
int arr[9] = { [0 ... 8] = 10 };
for (int i=0; i<9; i++)
printf("%d\n", arr[i]);
return 0;
}Output (for gcc only)
2
3
4
5
6
7
8
910
10
10
10
10
10
10
10
10Copy
We can also combine this with our old initializer list elements!
For example, I am setting only array index
arr[0], arr[8]as 0, while the others are designated initialized to 10!
2
3
4
5
6
7
8#include <stdio.h>
int main() {
int arr[9] = { 0, [1 ... 7] = 10, 0 };
for (int i=0; i<9; i++)
printf("%d\n", arr[i]);
return 0;
}Copy
Output
2
3
4
5
6
7
8
90
10
10
10
10
10
10
10
0
仅在gcc下能通过,同时三个点两旁必须有空格……还真是抽象啊
还有一个
char s[] = “12345”; int m = sizeof(s);
m的值是
答案是6,真的是6了我这个老6。看到答案才想起来,c里的char字符串后面有个\0表示结束。
Vue
这学期写了不少Vue前端,有几个点当时记了下来
watch的深度
一开始用watch检测某个数组的变化,结果发现并没有检测到。读了官方文档(同学们,真的是这样,一定要多读官方文档啊,非常的重要)后方才晓得,检测数组要加上deep才行。
watch默认是浅层的:被侦听的属性,仅在被赋新值时,才会触发回调函数——而嵌套属性的变化不会触发。如果想侦听所有嵌套的变更,你需要深层侦听器:
2
3
4
5
6
7
8
9
10
11
12export default {
watch: {
someObject: {
handler(newValue, oldValue) {
// 注意:在嵌套的变更中,
// 只要没有替换对象本身,
// 那么这里的 `newValue` 和 `oldValue` 相同
},
deep: true
}
}
}深度侦听需要遍历被侦听对象中的所有嵌套的属性,当用于大型数据结构时,开销很大。因此请只在必要时才使用它,并且要留意性能。
package-lock.json
某次开发时,嫌弃package-lock.json变来变去几万行,干脆把它给删了,加到了gitignore里,结果弄巧成拙,后来的同学根本跑不起来。
事实上,package.json记录的是依赖的元文件,而package-lock.json记录了确切的版本,锁定了依赖的版本,这使得所有人运行的项目都有完全相同的依赖,以确保大家都能跑起来。
经验教训:package-lock.json不能加到gitignore
两种import的方式
import LoginReminder from ‘@/components/LoginReminder’;
和import {LoginReminder} from ‘@/components/LoginReminder’;有什么区别
这两种方式导入LoginReminder组件的区别在于导入方式不同,最终得到的变量不同。
1 import LoginReminder from '@/components/LoginReminder';
这种方式是使用export default语法导出的组件。在另一个文件中使用import导入时,你可以自由地命名导入的变量名。例如:
1 | |
在这个例子中,我们没有指定导入的变量名,而是自己定义了一个名称为MyLoginReminder的变量作为导入的组件。
2 import {LoginReminder} from '@/components/LoginReminder';
这种方式是使用export语法导出的组件。在导入时,和导出时使用的变量名需要完全一致。例如:
1 | |
在这个例子中,我们使用了export const语法来导出组件,同时也给导出的变量起了一个名字LoginReminder。在导入时,我们需要使用完全相同的变量名LoginReminder来引用该组件。注意,在import语句中,需要用花括号将变量名包裹起来。
综上所述,无论是哪种方式,导入的都是组件的对象,只不过使用的变量名不同。
JS
== ===
碰到两三回这个错误了,de了半天bug,发现是==把字符串和数字比较了,甚至还返回true了(例如,'1' == 1,1 + '0' = 10这种逆天的语法,我真的这辈子都无法理解)。
让ChatGPT来说明一下==和===的区别。简单来说就是==不会比较类型,但是===会。
在JavaScript中,”==”和”===”是用于比较两个值的操作符。它们之间的区别如下:
- “==” 操作符是相等比较,它会进行类型转换。如果比较的两个值类型不同,它们会被转换为一个公共类型,然后再进行比较。
- “===” 操作符是严格相等比较,它不会进行类型转换。只有当比较的两个值类型相同并且值也相等时,才会返回 true。
下面是几个例子来说明它们之间的区别:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17javascriptCopy Code// 示例1: 相等比较, 类型转换
console.log(1 == "1"); // 输出: true, 数字1 被转换为字符串 "1" 进行比较
// 示例2: 严格相等比较, 不进行类型转换
console.log(1 === "1"); // 输出: false, 数字1 和字符串 "1" 类型不同
// 示例3: 相等比较, 类型转换
console.log(true == 1); // 输出: true, 布尔值true 被转换为数字1 进行比较
// 示例4: 严格相等比较, 不进行类型转换
console.log(true === 1); // 输出: false, 布尔值true 和数字1 类型不同
// 示例5: 相等比较, 类型转换
console.log(null == undefined); // 输出: true, null 和 undefined 被认为是相等的特殊情况
// 示例6: 严格相等比较, 不进行类型转换
console.log(null === undefined); // 输出: false, null 和 undefined 类型不同总结一下,”==” 允许类型不同的值进行比较时进行类型转换,而 “===” 需要比较的两个值类型相同。在大多数情况下,建议使用”===”进行严格相等比较,这样可以避免类型转换可能带来的意外结果。
他说的对
forEach map 区别
简单来说,forEach是void函数,作用在原数组上;map是返回一个新数组
还是让ChatGPT来解释一下吧
在JavaScript中,
forEach和map都是用于遍历数组的方法,但它们之间有一些区别。下面是它们的区别及相应的例子:
forEach:forEach方法用于遍历数组的每个元素,并对每个元素执行指定的回调函数。在forEach的回调函数中,我们可以对当前元素进行操作,但无法改变原始数组的内容。
2
3
4
5
6
7
8
9
10javascriptCopy Codeconst arr = [1, 2, 3];
arr.forEach((num) => {
console.log(num * 2); // 对每个元素乘以2并输出
});
// 输出:
// 2
// 4
// 6
map:map方法也用于遍历数组的每个元素,但它会返回一个新的数组,该数组包含了对原始数组每个元素进行处理后得到的结果。在map的回调函数中,我们可以对当前元素进行操作,并返回一个新的值。
2
3
4
5
6
7javascriptCopy Codeconst arr = [1, 2, 3];
const newArr = arr.map((num) => {
return num * 2; // 对每个元素乘以2并返回新的值
});
console.log(newArr); // 输出: [2, 4, 6]总结一下两者的区别:
forEach没有返回值,仅用于遍历数组执行操作,不能改变原始数组;map返回一个新的数组,其中包含对原始数组每个元素进行处理后的结果。因此,如果只需要遍历数组并执行一些操作而不需要返回新的数组,可以使用
forEach;如果需要对原始数组进行处理并返回一个新的数组,可以使用map。
Python
事实上,这学期的大多数Python代码是ChatGPT帮我写的……无论是简单的深度学习代码,还是数据处理的代码。
这学期碰到过一个很有意思的bug。当时我用Python从网上下载下来图片,然后按照Excel中的数据存到本地,但是在保存时有几个文件保存的格式并不成功,检查后发现是因为部分文件名含有特殊字符“/”,例如“张A/xx公司.jpg“,从而导致Python在存储时将张A识别成了文件夹。解决方法是提前replace这类字符串,将/换成其他字符即可。注意replace方法是返回一个新str,而不是修改原先的str
Java
Field injection is not recommended
尽管字段注入可能看起来很方便,但是它存在一些问题:
- 与构造函数和 Setter 注入相比,字段注入不容易进行单元测试。这是因为在使用字段注入时,需要直接修改字段的值,而在测试中,如果要注入其他的测试值,则需要使用反射机制才能修改字段的值。
- 字段注入会使得代码更加难以理解和维护。当读取代码时,无法立即知道该字段是如何被注入的,因为字段注入是隐式的,而构造函数注入和 Setter 注入则更加明确。
- 字段注入可能导致类之间的紧耦合关系增加。如果一个类使用了另一个类的字段,那么这两个类就会产生紧密的耦合,降低了代码的灵活性和可维护性。
因此,虽然字段注入看起来很方便,但是为了保持代码的可测试性、可读性和可维护性,仍然建议使用构造函数注入和 Setter 注入来替代字段注入。
Redis
遇到一个bug,是想在redis里存时间,结果报错称Java 8 date/time type java.time.LocalDate not supported by default。当时比较忙,时间紧张下直接用了比较无脑的方法:先转成String存进去,取出来再转成LocalDate……实际上更好的方法是自己添加序列化和反序列化器,这里由于笔者也未继续实践,就不多写了。
前端
建议还是认真读完一遍前端UI文档再来开发,会效率高很多。至少也得大致过一遍,才能知道一些比较少见的用法。之前只是草草看了一遍Vue的文档,很多概念还是模糊。这学期再看了一次,不仅学到了slot的用法,还对watch的深度有了了解,这些知识在debug时相当有帮助,可以提升定位bug的速度。
小程序
这学期有幸体验了下微信小程序开发,也算颇有一些心得。首先值得吐槽的点是,小程序的文档好难找orz而且一开始我以为它只有视频的文档,把我给看傻了,后来才发现左边的目录栏是可以展开的…在此处附上link
https://developers.weixin.qq.com/miniprogram/dev/framework/
好在有一众网上教程和Chat老师的教导,因此上手也比较快,个人理解来看就是一个小号的Vue,封装了比较多wx相关的api。当然使用的时候也遇到过一些坑,比如某些api不是在所有平台上都通用的,这就导致本地运行时的效果很正常,但是交给客户时试用反而有不同。
css
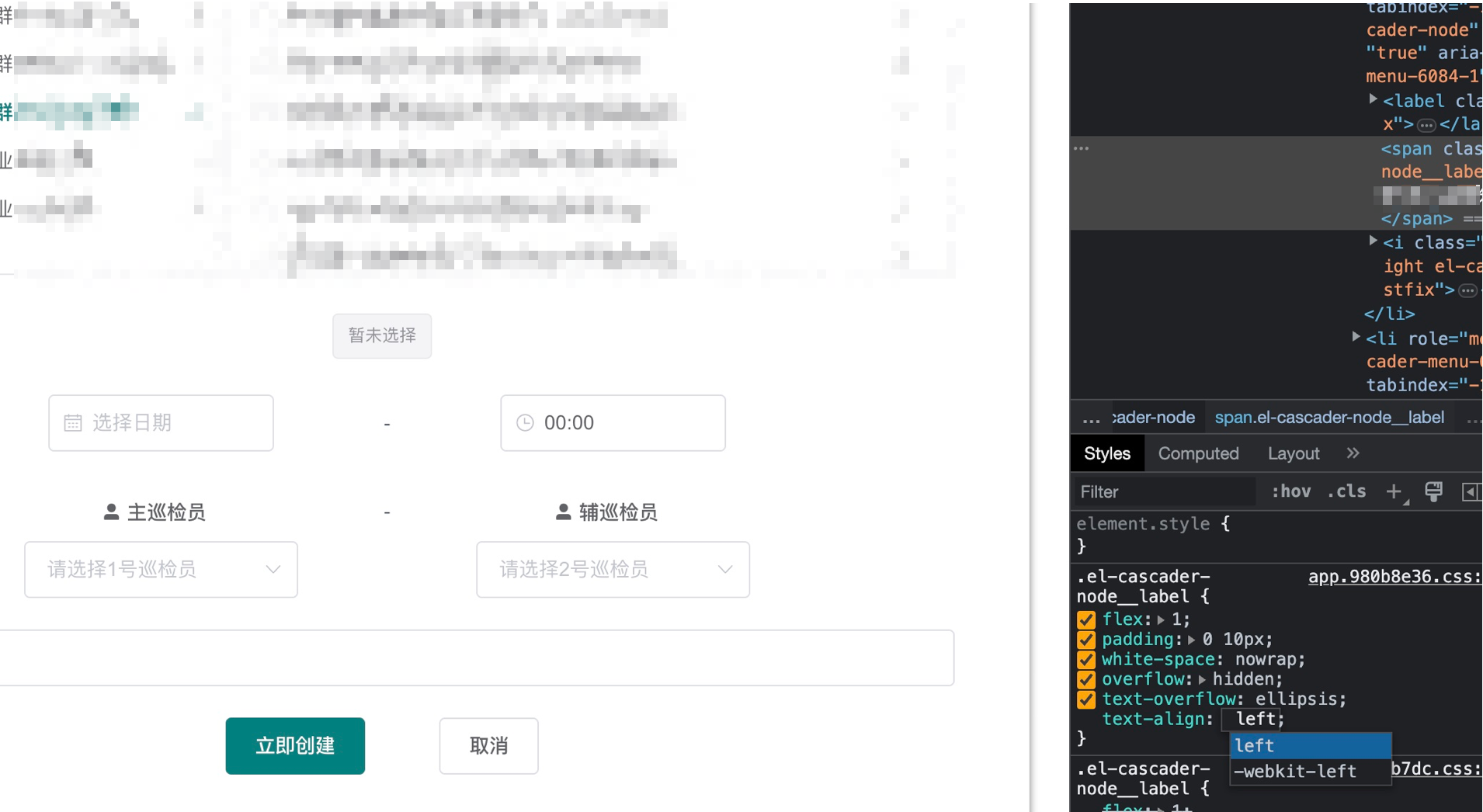
找css样式的正确方法:打开F12控制台,直接点对应的区域,会显示对应的css style。遇到特别刁钻的需求时可以对着弄。
pip和conda的区别
pip install 和 conda install 都是用于安装 Python 包和库的命令,但是它们使用的包管理工具和适用范围有所不同。
pip 是 Python 官方推荐的包管理工具,可以在全局环境或虚拟环境中使用。它可以从 Python Package Index (PyPI) 中下载并安装 Python 模块、包和库,并且可以安装其他的二进制文件。通过 pip install 命令安装的包一般都是纯 Python 代码实现的,如果需要依赖某些 C 或 C++ 编写的扩展模块,通常需要手动安装这些模块的编译环境。因此,使用 pip 安装的包可能会存在兼容性和性能问题。
而 conda 则是 Anaconda 发行版自带的包管理工具,也可以在全局环境或虚拟环境中使用。它除了可以下载和安装 Python 包外,还可以安装二进制文件、文档和依赖库。conda 拥有自己的包仓库,叫做 Anaconda 仓库,其中包含了大量的科学计算和数据分析相关的 Python 包。conda 能够处理多平台、多版本、多依赖关系的情况,可以自动安装相关的依赖包及其编译环境,从而避免了很多兼容性和性能方面的问题。
总之,如果您使用 Python 进行科学计算和数据分析等工作,建议使用 Anaconda 发行版,并使用 conda 命令来管理包的安装,这样可以保证软件环境的稳定性和完整性。如果您只是在轻量级的 Python 项目中使用一些简单的纯 Python 包,那么使用 pip 工具已经足够了。
我个人一般这样管理Python环境:
使用conda管理系统里的所有Python管理
1
2
3
4
5
6conda env list # 查看所有Python环境
conda create --name lab3 python=3.8 # 创建py38环境
conda create -f environment.yaml # 根据environment.yaml的信息创建Python环境
conda activate lab3 # 激活环境
conda deactivate # 取消激活
conda remove -n software-testing -all # 删除环境在每个Python环境里使用pip管理Python的包
1
2
3
4
5pip list
pip install pandas
pip uninstall pandas
# pip freeze | tee requirements.txt # pip其实也可以导出,不过我不是很常用就是了
# pip install -r requirement.txt # pip也可以导入使用conda导出Python环境,以便在多个设备使用
1
conda env export > environment.yaml # 导出当前环境的信息到environment.yaml